Working with SquareShift: Clarity Before the First Call
Transparency starts before the first sales conversation. Understand our 4 engagement tiers, 3 procurement models, and 5-phase delivery lifecycle — then decide if we’re the right fit for your Elastic needs.
8-16 hour rapid assessment. See what’s broken. Get recommendations.
45-minute discovery call. Discuss your Elastic challenge and our approach.
4 Engagement Tiers: Choose Your Starting Point
Each tier includes dedicated Elastic expertise, defined deliverables, and a clear timeline. Start with a Health Check or go straight to a Solution Build. You control the scope.
Elastic Health Check
Organizations needing a rapid expert assessment of their Elastic deployment’s health, performance, or cost efficiency.
Typical Deliverables
- Assessment report: architecture review, performance bottlenecks, cost optimization opportunities
- Risk register: security gaps, compliance issues, scalability concerns
- Prioritized recommendations with effort estimates
Example Use Cases
- Is our Elastic architecture production-ready?
- Why is our observability bill growing 30% month over month?
- Can we pass our SOC2 audit with our current SIEM configuration?
Elastic Migration Program
Enterprises migrating from Splunk, Datadog, New Relic, or legacy Elasticsearch with complex data pipelines and zero-downtime requirements.
Typical Deliverables
- Migration strategy document: source analysis, target architecture, data flow mapping
- Zero-downtime migration plan: cutover strategy, rollback plan, validation testing
- Runbook and knowledge transfer documentation
- Post-migration optimization recommendations
Example Use Cases
- We’re moving 2TB+ from Splunk to Elasticsearch without downtime
- Datadog is costing $500K/year; we need to consolidate to Elastic
- Our OpenSearch deployment is unstable; we need expert migration help
Elastic Solution Build
Greenfield Elastic deployments — enterprise search, observability platforms, SIEM/security — requiring architecture design through production hardening.
Typical Deliverables
- Solution architecture document: capacity planning, HA/DR design, security architecture
- Sprint-based delivery with automated testing and staging validation
- Runbook creation, SLA definition, and operational playbooks
- Training and enablement for internal teams
Example Use Cases
- We’re building a new e-commerce search platform on Elasticsearch
- We need a greenfield SIEM to pass our first SOC2 audit
- We’re consolidating 5 observability tools into Elastic
Elastic Managed Services
Organizations needing 24/7 operational coverage, proactive optimization, and continuous improvement of production Elastic environments.
Typical Deliverables
- SLA-backed response times: P1 incidents within 30 minutes, P2 within 4 hours, P3 within 24 hours
- Proactive monitoring and alerting with escalation paths
- Monthly cost optimization and performance tuning
- Quarterly architecture reviews and roadmap alignment
Example Use Cases
- Our team doesn’t have Elastic expertise; we need 24/7 coverage
- We need proactive optimization and cost management for production clusters
- Our production Elastic environment is business-critical; we can’t afford downtime
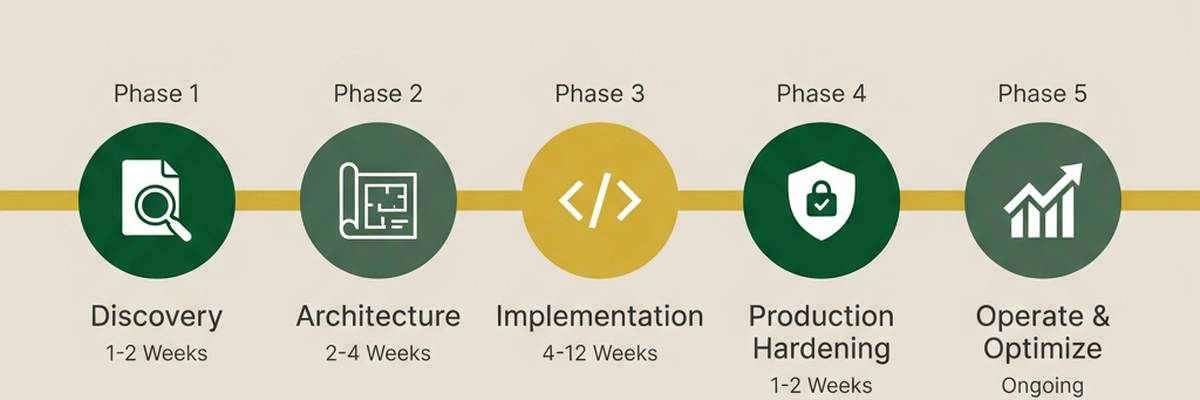
Our 5-Phase Delivery Lifecycle
Every Elastic engagement follows a proven methodology with defined deliverables, acceptance criteria, and sign-off gates at each phase. No ad hoc consulting. No undefined scope.
Phase 1: Discovery
Understand current state. Define target state. Identify gaps.
- Current architecture assessment
- Stakeholder interviews and requirements gathering
- Risk and compliance assessment
- Success criteria definition
- Assessment report: architecture review, performance analysis, cost baseline
- Risk register: security gaps, compliance issues, technical debt
- Scope-of-work document with acceptance criteria
Deployed: Blast Radius (impact analysis), Topology Builder (architecture visibility)
Gate: Stakeholder sign-off on assessment findings and scope-of-work document.
Phase 2: Architecture
Design target architecture. Plan migration or implementation. Define capacity and cost.
- Solution architecture design: cluster sizing, HA/DR, security architecture
- Capacity planning and cost modeling
- Migration strategy or greenfield implementation plan
- Test plan and acceptance criteria definition
- Solution architecture document: Elasticsearch cluster design, data flow diagrams, network topology
- Capacity plan: node sizing, storage estimates, ingestion rates
- Migration strategy: zero-downtime approach, data validation plan, rollback strategy
- Test plan with automated test scripts
Deployed: Topology Builder (dependency mapping), Cost Optimization Engine (capacity planning)
Gate: Architecture review and sign-off by designated stakeholder.
Phase 3: Implementation
Build, test, and validate in staging. Prepare for production deployment.
- Sprint-based delivery in 2-week sprints
- Automated testing: unit, integration, performance, security
- Staging validation with production-like data
- Runbook and playbook creation
- Deployed Elasticsearch environment: staging + production
- Automated test suites integrated into CI/CD pipelines
- Migration execution with data validation reports (if applicable)
- Runbook documentation: operational procedures, incident response, troubleshooting
Deployed: All 9 accelerators as applicable — Alarm Noise Suppression, AI Triage Assistant, Log Reduction Engine, Compliance Reporter, and others based on engagement scope.
Gate: Staging validation passed. Production deployment approved by stakeholder.
Phase 4: Production Hardening
Optimize performance. Tune alerts. Validate SLAs. Prepare for operational handoff.
- Performance tuning: query optimization, indexing strategy, cluster tuning
- Alert tuning and false-positive reduction
- SLA validation and operational readiness testing
- Knowledge transfer and training sessions
- Performance tuning report: query optimization, indexing improvements, cost reductions
- SLA definition document: uptime targets, response times, escalation paths
- Training materials and knowledge transfer sessions
- Operational handoff documentation
Deployed: Alarm Noise Suppression (alert tuning), Compliance Reporter (audit readiness)
Gate: SLA targets met. Team training completed. Operational handoff accepted.
Phase 5: Operate & Optimize
Monitor, optimize, and iterate. Continuous improvement, not abandonment.
- Proactive monitoring and alerting
- Quarterly cost optimization reviews
- Continuous performance tuning
- Roadmap alignment and feature expansion
- Monthly operational reports: uptime, incident summary, cost trends
- Quarterly optimization recommendations: cost savings, performance improvements
- Ongoing SLA-backed support (Managed Services tier)
- Annual architecture reviews
Deployed: All accelerators continuously updated. New accelerators added as requirements evolve.
Gate: SLA compliance sustained. Continuous improvement demonstrated through quarterly reviews.
3 Procurement Models: Flexible Engagement Structures
Time & Materials, Statement of Work, or Managed Services — each structured for different Elastic engagement types and enterprise procurement requirements. You choose the contract model.
Time & Materials (T&M)
Flexible engagement for evolving requirements. Elastic health checks, advisory work, and exploratory assessments billed per consultant-day with weekly status reports and full cost visibility.
Best For
- Elastic health checks and rapid assessments
- Advisory consulting: architecture reviews, expert guidance
- Exploratory projects with undefined scope
- Ongoing Elastic support (non-SLA-backed)
Billing Structure
- Hourly or daily rates by role (Principal Consultant, Elastic Engineer, etc.)
- Weekly timesheets and status reports
- Monthly invoicing with detailed breakdowns
- Budget cap with written approval required for overages
Typical Use Cases
- We need 3 days of Elastic architecture consulting
- Help us troubleshoot our production cluster for a week
- We want ongoing advisory support — 10-20 hours per month
Master Services Agreement (MSA) with purchase orders per engagement.
Example Clause Extract (Redacted):
“Consultant will invoice Client on a weekly basis for services rendered, calculated at [RATE] per hour for Principal Consultant role and [RATE] per hour for Engineer role. Total engagement costs shall not exceed [BUDGET CAP] without prior written approval from Client’s designated project sponsor.”
Statement of Work (SOW)
Fixed-scope Elastic engagement with defined acceptance criteria, test evidence, and runbook handoff. Milestones, deliverables, and sign-off gates included. Built for migrations, SIEM deployments, and search implementations with clear scope.
Best For
- Splunk, Datadog, or New Relic migrations to Elasticsearch
- Greenfield SIEM deployments for SOC2/PCI-DSS compliance
- Enterprise search implementations
- Observability platform consolidation projects
Billing Structure
- Fixed price per SOW based on defined scope and effort estimates
- Milestone-based payments: 25% at kickoff, 25% at architecture sign-off, 30% at production deployment, 20% at final acceptance
- Formal change order process for scope changes
Typical Use Cases
- Migrate 2TB from Splunk to Elasticsearch in 12 weeks with zero downtime
- Build a production-ready SIEM to pass our SOC2 audit
- Consolidate 5 observability tools into Elasticsearch
Statement of Work document with acceptance criteria, deliverables, timelines, and formal change order process.
Example Clause Extract (Redacted):
“Consultant shall deliver the following milestones: (1) Discovery & Architecture Blueprint [DATE], (2) Implementation Phase 1 [DATE], (3) Production Readiness [DATE]. Payment terms: 30% upon SOW signature, 40% upon Architecture approval, 30% upon final delivery and client acceptance.”
Managed Services Agreement
Ongoing operational responsibility with SLA-backed response times, proactive optimization, and continuous improvement. Monthly retainer with defined coverage hours, escalation paths, and reporting cadence.
Best For
- 24/7 operational coverage for production Elastic environments
- Organizations without internal Elastic expertise
- Business-critical Elastic deployments requiring guaranteed uptime
- Proactive cost optimization and performance tuning
Billing Structure
- Monthly retainer tiered by environment size and SLA requirements
- SLA-backed response times: P1 within 30 minutes, P2 within 4 hours, P3 within 24 hours
- Proactive monitoring, alerting, and optimization included
- Service credits for SLA breaches (contractual, not aspirational)
Typical Use Cases
- We need 24/7 Elastic operations support with sub-30-minute P1 response
- Our production SIEM is business-critical; we can’t afford downtime
- We want proactive cost optimization and quarterly architecture reviews
Managed Services Agreement (MSA) with SLA commitments, escalation paths, and termination clauses.
Example Clause Extract (Redacted):
“SLA Coverage: 24/7 monitoring with 15-minute incident response time for P1 issues, 2-hour response for P2 issues. Service credits apply if SLA targets are not met: [PERCENTAGE] of monthly fee credited for each breach. Contract term: [DURATION] with 90-day termination notice required.”
Who You’ll Work With: Our Elastic Team
Every engagement includes certified Elastic consultants, solution architects, and engineers. 60+ Elastic certifications across the team. 60+ production implementations delivered.
Principal Consultant
- Lead discovery, architecture, and implementation strategy
- 60+ Elastic migrations and deployments
- Platform design, capacity planning, and best practices
10+ years Elasticsearch experience. ElasticON speaker. 20+ customer implementations.
Solution Architect
- Cluster design, capacity planning, HA/DR architecture
- Security architecture and compliance design
- Migration strategy and zero-downtime planning
8+ years infrastructure architecture. Elastic cluster sizing expert. 15+ migrations.
Elastic Engineer
- Implementation, configuration, and performance tuning
- Kibana dashboard development and APM specialization
- Troubleshooting and production optimization
5+ years Elasticsearch implementation. Kibana dashboard expert. APM specialist.
Site Reliability Engineer
- Production monitoring and incident response
- Performance tuning and optimization
- 24/7 SLA management and escalation
7+ years SRE experience. 24/7 on-call rotation. P1 incident response expert.
Project Manager
- Sprint planning and stakeholder communication
- Risk management and timeline tracking
- Change order coordination and budget management
10+ years technical project management. Elastic migration specialist.
Common Questions About Working with Us
It depends on the engagement tier, but here are the benchmarks we commit to:
Health Check: 1-2 weeks from kickoff to assessment report delivery. You’ll have a full architecture review, risk register, and prioritized recommendations.
Migration Program: 8-16 weeks from discovery to production cutover. This includes architecture design, staging validation, zero-downtime migration execution, and knowledge transfer.
Solution Build: 12-24 weeks from kickoff to production hardening. Sprint-based delivery with sign-off gates at each phase means you have visibility and control throughout.
Managed Services: 2-4 weeks to onboard and transition operational responsibility. After onboarding, coverage is continuous.
We provide detailed timeline estimates after the initial discovery phase and commit to milestone-based delivery with sign-off gates. If you want to see how this looks in practice, review our 5-Phase Delivery Lifecycle above.
Scope changes happen. The question is whether they’re governed or chaotic.
For SOW engagements, we follow a formal change order process:
1. Document the scope change request with business justification
2. Estimate effort and cost impact
3. Obtain written approval from your designated project sponsor before proceeding
No work begins on scope changes until you approve in writing. Every change is version-controlled and tracked.
For T&M engagements, scope adjustments are reflected in weekly status reports and approved via your preferred channel (email, Slack, or project management tool). All changes are transparent, documented, and approved before implementation.
View our change order process in detailWe build accountability into every contract.
For SOW engagements, milestone delays trigger a formal escalation process:
1. Root cause analysis within 48 hours
2. Recovery plan with revised timeline
3. Compensation discussion: credit toward future work or extended support at no additional cost
For Managed Services, SLA breaches trigger service credits per our agreement terms. Typical structure: 10-25% of the monthly fee credited per breach. We track SLA compliance monthly and report transparently — you see the same dashboard we do.
No fine print. No ambiguity. If we miss, you’re compensated.
View a sample SLA compliance reportWe follow least-privilege access principles by default:
1. Read-only access to production logs and metrics for assessment and troubleshooting
2. Write access only during approved maintenance windows with your authorization
3. No customer data export without written approval
For regulated industries (HIPAA, PCI-DSS, SOX), we offer data masking, on-premises deployment options, and BAA/DPA agreements. All consultants sign NDAs and complete security training before engagement start.
We don’t need your data to do our job well. We need access to your system metrics and configurations.
Yes. Our engagement tiers are designed to be modular.
Most organizations start with a Health Check (8-16 hours) to assess fit and define scope. From there, you expand to Migration, Solution Build, or Managed Services based on assessment findings.
A typical path: Health Check identifies architecture gaps. Migration engagement addresses them. Managed Services sustains the result.
You control the pace, scope, and commitment level at each step. There is no all-or-nothing engagement requirement.
Explore our engagement tiers above to find your starting point.
Every engagement includes structured knowledge transfer. This is not optional — it’s built into the scope.
What you receive:
1. Runbook documentation: operational procedures, troubleshooting guides, incident response playbooks
2. Training sessions: architecture walkthroughs, query optimization workshops, dashboard creation tutorials
3. Q&A office hours: 30-60 days of post-handoff access to your engagement team for questions and guidance
We believe in building your team’s capability, not creating dependency on ours. The goal of every engagement is that your team can operate independently after handoff.
Managed Services clients receive ongoing training as part of their retainer — no separate knowledge transfer phase needed.
Still have questions about our process?
Book a 30-Minute Q&A CallReady to Start? Choose Your Engagement Tier.
Start with a Health Check to assess fit, or book a consultation to discuss your Elastic challenge directly. We respond to every inquiry within 24 hours.
8-16 hour rapid assessment. See what’s broken. Get recommendations.
45-minute discovery call. Discuss your challenge and our approach.
24-Hour Response Commitment: We respond to all engagement inquiries within 24 hours. No auto-responders. Real consultants.