Elastic Managed Services: 24/7 Coverage. SLA-Backed. Team Continuity.
The same team that built your Elasticsearch environment now runs it. Proactive monitoring. Incident response. Continuous optimization. Cost transparency. 24-hour response SLA -- not best-effort, not escalation-dependent, not a premium tier add-on. Included in every tier.
Ready to move forward? Select your tier and get custom pricing.
Not sure if this is right? Schedule a 15-minute consultation.

THE COST OF DIY OPERATIONS
Why Enterprises Choose Managed Services Over DIY Operations
Running production Elasticsearch in-house is expensive, risky, and distracts your team from strategic work.
Your SREs Spend 60%+ Time Firefighting
Cluster health monitoring. Shard rebalancing. Memory issues. Query performance tuning. Your SREs spend more than half their time on Elasticsearch operations instead of building features. That is engineering capacity you are paying for but not getting.
See how 24/7 SRE coverage eliminates thisP1 Incidents at 2am. Resolution Takes Hours.
Your on-call engineer is exhausted. They are unfamiliar with edge cases. The runbook is outdated or missing. P1 resolution takes 2+ hours because you are relying on one person's memory at 2am. Every hour of downtime costs revenue and erodes customer trust.
See our P1 incident modelOver-Provisioned by 30-40%. Wasting $6K-$8K/Month.
Your Elasticsearch cluster is burning money on unused capacity. You know it is over-provisioned, but you lack the tooling and dedicated time to optimize continuously. Scaling down feels risky. So the waste continues, month after month. Your CFO notices.
See cost optimization acceleratorsTwo Experts Leave. Institutional Knowledge Goes with Them.
Elasticsearch expertise is rare and expensive. Your team has 1-2 specialists. If they leave, you lose institutional knowledge that took years to build. No runbooks capture what they know. No documentation covers the edge cases they solved. You are one resignation away from operational risk.
See team continuity guaranteeWHAT IS INCLUDED
What You Get with SquareShift Managed Services
Proactive, not reactive. Optimized, not over-provisioned. Transparent, not opaque.
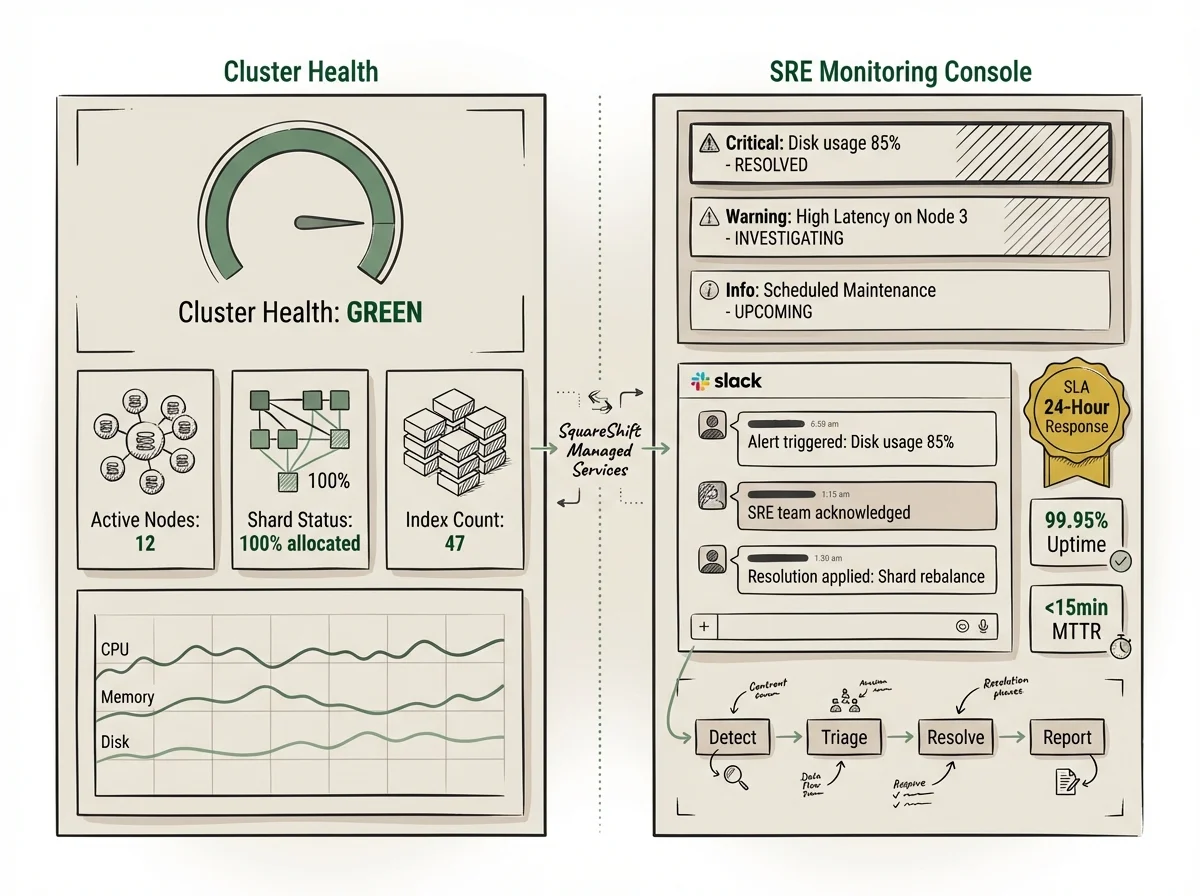
24/7 Cluster Health Monitoring
Real-time monitoring, alert management, anomaly detection across your entire Elasticsearch environment. Issues caught before they become incidents.
Catch issues at 11pm before your customers notice at 9am.
Proactive Cost & Performance Optimization
Weekly performance tuning, cost optimization, capacity planning. Reduce costs 20-30%. Improve query performance 15-25%.
Your cluster gets faster and cheaper every month, not just maintained.
SLA-Backed Incident Response
P1/P2/P3 incident triage, root cause analysis, resolution, and post-mortem. Reduce MTTR from hours to minutes.
P1 incidents resolved in minutes, not hours. Every incident gets a post-mortem.
Quarterly Capacity Planning & Forecasting
Quarterly capacity reviews, growth forecasting, scaling recommendations. Avoid over-provisioning (waste) and under-provisioning (downtime).
Scale ahead of demand. No surprises. No emergency scaling events.
Monthly Architecture Reviews & Upgrades
Monthly architecture reviews, accelerator integration, best practices implementation. Your environment evolves with Elasticsearch releases and your business needs.
Your Elasticsearch environment gets better every month, not just stable.
CFO-Ready Cost Reports & Dashboards
Monthly cost reports, utilization dashboards, optimization recommendations. Every dollar accounted for. Every saving documented.
Your CFO sees exactly what you spend and exactly what you save. No black box.
THREE-PHASE MODEL
Three Phases: Onboarding. Steady-State Operations. Continuous Optimization.
Smooth handoff. Predictable operations. Measurable improvements.
Phase 1: Onboarding
Environment audit, runbook review, knowledge transfer, team training (live sessions + documentation), Slack/Teams integration, integration with existing incident response tools (PagerDuty, Opsgenie), SLA baseline establishment. 24-hour response SLA begins on Day 1 -- not after a 90-day ramp-up.
See Onboarding Checklist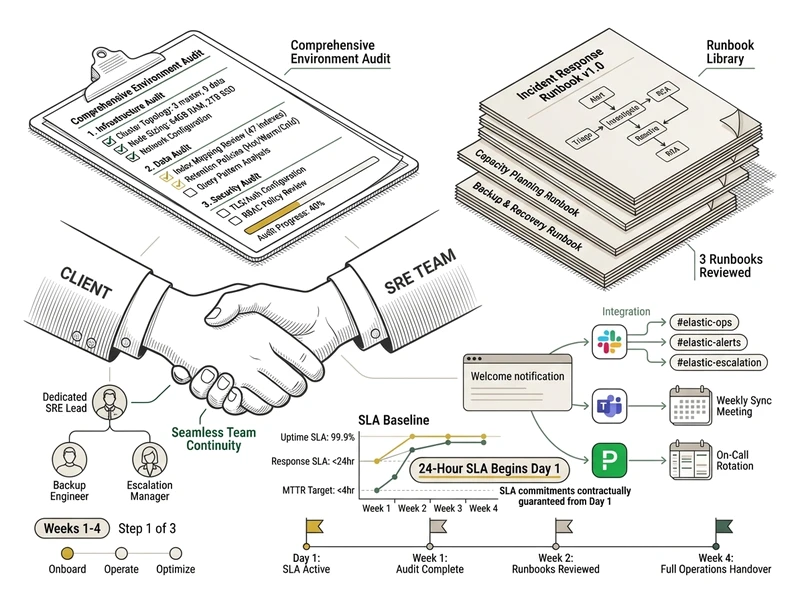
Phase 2: Steady-State Operations
24/7 monitoring, alert management, incident response (P1/P2/P3), weekly health reports, monthly cost reports, quarterly capacity reviews. SquareShift's SRE team handles all operational complexity; your team scales capacity without needing Elasticsearch expertise. SLA-backed uptime guarantee active and tracked.
View Sample Health Report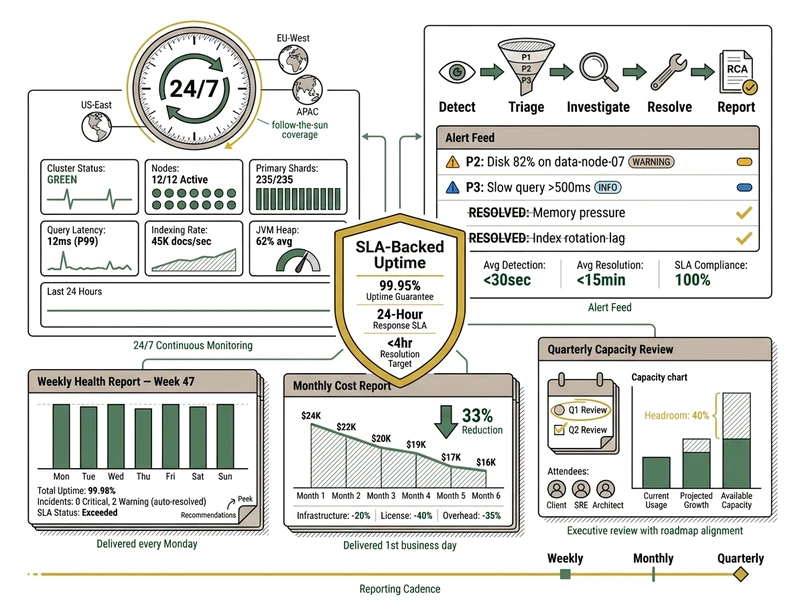
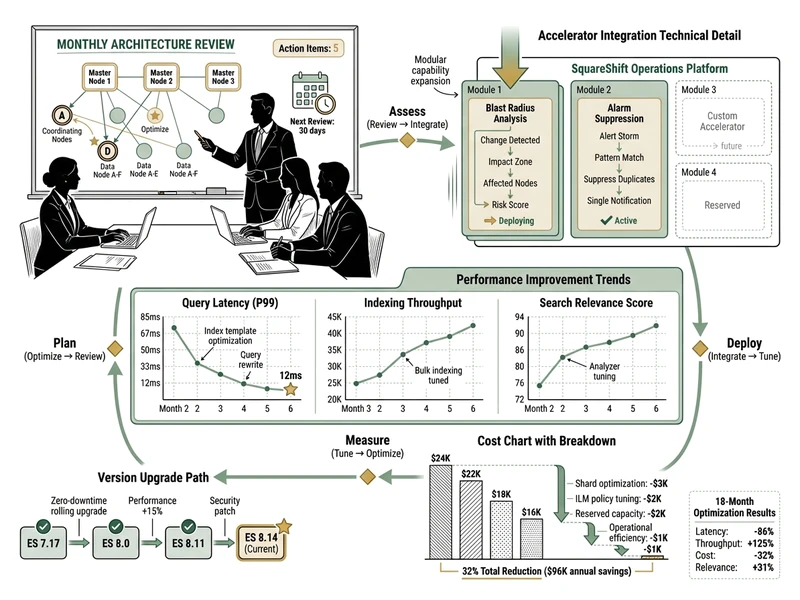
Phase 3: Continuous Optimization
Monthly architecture reviews, accelerator integration (Blast Radius, Alarm Noise Suppression, Log Reduction Engine), performance tuning, cost optimization, Elasticsearch version upgrades, best practices implementation. Your environment gets measurably better every quarter.
WHY SQUARESHIFT
SquareShift vs. DIY, Elastic Support, and Generic MSPs
Team continuity. Elasticsearch depth. Proactive optimization. Cost transparency. Here is how we compare.
| Capability | SquareShift | DIY (In-House) | Elastic Support | Generic MSP |
|---|---|---|---|---|
| Team Continuity | Same engineers from implementation | Knowledge loss if experts leave | No implementation context | Generalist engineers rotating |
| 24-Hour Response SLA | All incidents, every tier | Depends on on-call availability | 4-hour SLA premium tier only | Best-effort, no contractual SLA |
| Proactive Optimization | Monthly reviews + accelerators | Reactive, no dedicated time | Reactive, ticket-based only | Keep-the-lights-on only |
| Cost Transparency | Monthly CFO-ready reports | No dedicated cost tracking | No cost transparency | Generic reporting |
| Elasticsearch Depth | 60+ implementations, Innovation Award | 1-2 specialists at best | Strong product knowledge | Documentation-level only |
| Accelerator Integration | Blast Radius, Alarm Suppression, Log Reduction -- included | No proprietary IP | Not available | No Elasticsearch tooling |
Their Strength: Complete control. Internal knowledge while experts remain employed.
We eliminate operational burden so your SREs focus on strategic work -- platform architecture, feature delivery, capacity strategy. Plus, we bring 60+ implementations of pattern recognition your internal team cannot replicate. Your 2 SREs have seen your 1 environment. We have seen 60+.
Their Strength: They built Elasticsearch. Deep product knowledge.
Elastic support is reactive: you file a ticket, they respond. We are proactive: we find issues before you notice them, optimize costs you did not know were wasted, and review your architecture monthly. Plus, we built your environment -- we know your shard strategy, your custom plugins, your edge cases.
Their Strength: Broad DevOps coverage across multiple platforms.
Generic MSPs lack Elasticsearch depth. They manage your cluster the same way they manage any infrastructure -- generalist playbooks, rotating engineers, no specialization. We are Elasticsearch specialists: 60+ implementations, Innovation Award, proprietary accelerators built from patterns across those 60+ environments.
PROPRIETARY IP INCLUDED
Accelerators Included in Every Managed Services Tier
Proprietary IP built from patterns across 60+ Elasticsearch environments. Reduces costs, improves performance, eliminates toil. Not add-ons. Included.
Blast Radius
Identifies at-risk services before deployment. Maps failure cascades across your Elasticsearch topology. Prevents production incidents before they happen.
"Prevented 8 production incidents in 6 months at an E-commerce platform. Each prevented incident = ~$25K in avoided downtime."
See DemoAlarm Noise Suppression
ML-powered alert suppression. Reduces false positives 80-90%. Your on-call engineer only gets paged for real incidents, not noise.
"Reduced on-call alert volume from 200/week to 15/week at a SaaS company. On-call burnout dropped. Retention improved."
See DemoLog Reduction Engine
Intelligent log sampling. Cuts storage costs 50-70% without losing diagnostic fidelity. You keep what matters; we compress the rest.
"Reduced Elasticsearch storage costs $8.3K/month (47%) at a FinTech company. Same diagnostic capability. Half the storage bill."
See DemoTopology Builder
Automatic service topology mapping from logs and metrics. See your entire Elasticsearch-connected architecture -- services, dependencies, data flows -- without manually documenting anything.
"Mapped 200+ microservices automatically. Replaced 3 months of manual architecture documentation. Updated in real-time."
See DemoENTERPRISE-GRADE OPERATIONS
Enterprise-Grade SLA. 24-Hour Response. Verified.
We have managed 60+ Elasticsearch environments across Fortune 500 enterprises and high-growth startups. Here is the proof.
24-Hour Response SLA
All incidents (P1/P2/P3) receive human response within 24 hours. Not automated acknowledgment. Human response.
View SLA compliance dashboardTeam Continuity
Same engineers from implementation continue as your managed services team. No handoff. No context loss. No ramp-up.
View team profilesRunbook Integration
All runbooks from implementation integrated into managed services operations. Documented, versioned, and maintained.
View sample runbookCost Transparency
Monthly cost reports with utilization metrics, savings proof, and optimization recommendations. Every dollar tracked.
View sample cost reportYour SRE Team's Credentials
Our managed services SRE team includes 8 Elastic Certified Engineers (ECE) with 120+ years combined Elasticsearch experience across 60+ production environments. Elastic Innovation Award winner (2024: Observability Innovation). ElasticON 2024/2025 conference speakers (3 sessions: Advanced Shard Optimization, Multi-Cluster Federation, GenAI Integration). Not generalist DevOps contractors -- Elasticsearch specialists who have seen every failure mode, every edge case, every scaling challenge your cluster will face.
Guaranteed human response -- not automated acknowledgment. Elastic charges premium for 4-hour SLA; we include 24-hour SLA in every tier. Tracked at /sla with 93% compliance over 12 months.
| Capability | SquareShift (All Tiers) | Elastic Support (Premium) | Generic MSP |
|---|---|---|---|
| Response SLA | 24-hour guaranteed (all tiers) | 4-hour SLA (premium only) | Best-effort. No SLA. |
| P1 Response | <1 hour (Enterprise), <4 hours (Professional) | 1-hour (premium only) | No P1 differentiation |
| SLA Tracking | Public dashboard. 93% compliance. | Available per contract | No tracking |
| Breach Protocol | Auto escalation + credit | Credit per contract terms | No protocol |
| Coverage Model | Dedicated SRE (Tier 3), named engineers | Ticketing system | Rotating engineers |
| Cost | Included in every tier | 4-hour SLA requires premium ($$$) | No SLA = no cost for SLA |
TRANSPARENT PRICING
Transparent Managed Services Pricing
Three tiers. Predictable monthly pricing. 24-hour response SLA included in every tier.
| Feature | Essential | Professional | Enterprise |
|---|---|---|---|
| Price | $5K/mo | Custom Pricing | Custom |
| Best For | Small clusters (<10 nodes), business-hours coverage | Medium clusters (10-50 nodes), 24/7 coverage, proactive optimization | Large clusters (50+ nodes), dedicated SRE team, custom SLA |
| Coverage Hours | 8am-5pm PT, Mon-Fri | 24/7 (around-the-clock) | 24/7 + dedicated escalation path |
| Response Time | 24-hour SLA (all incidents) | 24-hour SLA (P2/P3), 4-hour SLA (P1) | 24-hour SLA (P2/P3), 1-hour SLA (P1) |
| Monitoring | Cluster health, basic alerts | Cluster health, advanced alerts, anomaly detection | Cluster health, advanced alerts, anomaly detection, custom dashboards |
| Optimization | Quarterly capacity reviews | Monthly architecture reviews, cost optimization | Weekly performance tuning, continuous optimization |
| Accelerators | None included (add-on available) | 2 accelerators included | All accelerators included |
| Team | Shared SRE team | Shared SRE + dedicated account manager | Dedicated SRE team (2-3 engineers) + dedicated account manager |
P1 incidents under 4 hours -- Elastic charges premium for this; SquareShift includes it in Tier 2.
Starting at $5K/month
Starting at $15K/month
Custom pricing
Pricing Questions
12 months for Tier 1 and Tier 2. 6 months for Tier 3 (negotiable based on scope). We earn your renewal through results, not lock-in.
Yes. 30-day notice. Pricing adjusts at the next billing cycle. If your cluster grows from 8 nodes to 25, you upgrade to Tier 2 and get 24/7 coverage + accelerators. If it shrinks, you downgrade. No penalties.
Tier 3 pricing depends on cluster size (50+ nodes), coverage requirements, custom SLA terms, and dedicated team composition. Schedule a consultation for a detailed quote. We provide a breakdown within 48 hours.
Included. Tier 2 includes 2 accelerators of your choice from our library. Tier 3 includes all accelerators. Tier 1 can add accelerators for an additional fee. No hidden costs.
Managed services pricing is separate from implementation and migration pricing. We scope additional work independently. View our full engagement models at /elastic/engagement-models.
Yes. 60-day notice after minimum contract term. We provide complete runbook handoff, knowledge transfer, and documentation. No penalties. No hostage-taking. If we are not delivering value, you should leave.
REAL RESULTS
Real Results from Real Managed Services Customers
Quantified outcomes from enterprises that transitioned from DIY operations to SquareShift managed services.
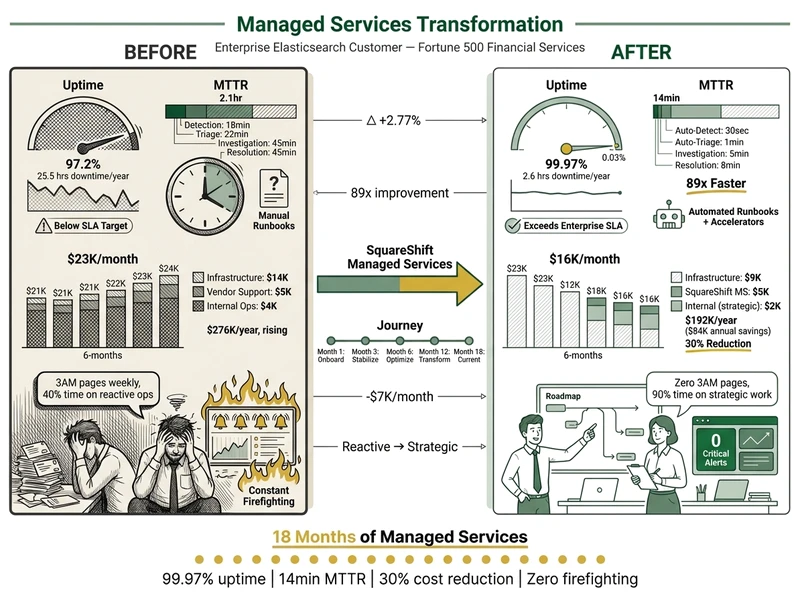
E-commerce Platform
300-person engineering team | Multi-region deployment | 2.4TB across 45 nodes
Challenge
Running Elasticsearch in-house with 2 dedicated SREs. Uptime averaging 97.2%. On-call burnout causing retention issues. Cluster over-provisioned by 35% -- wasting $8K/month on unused capacity. P1 incidents averaging 2.1 hours to resolve.
Solution
Transitioned to SquareShift Managed Services (Tier 2: Professional). 24/7 coverage. Proactive optimization. Accelerator integration: Alarm Noise Suppression (reduced alert noise 85%) + Log Reduction Engine (cut storage costs 47%).
Results
- Uptime: 97.2% → 99.97% (2.8 point improvement)
- MTTR: 2.1 hours → 14 minutes (89% reduction)
- Costs: $23K/mo → $16K/mo (30% reduction, $7K/mo savings)
- SRE Time: 60%+ capacity redirected to platform strategy
- Alert Volume: Reduced 85%; on-call rotation weekly → monthly
YOUR QUESTIONS ANSWERED
Common Questions About Managed Services
Direct answers to the 6 concerns we hear most from engineering leaders evaluating managed services.
Managed services typically costs 30-50% less than in-house operations. Here is the math: 2 SREs at $175K/year = $350K in salary alone. Add benefits, overhead, training, and on-call compensation = ~$450K/year. Tier 2 managed services: $180K/year + proactive optimization that reduces your Elasticsearch costs 20-30% -- savings that offset the managed services fee. Net: you pay less AND get better outcomes.
Calculate your own TCOOur 24-hour response SLA is tracked in HubSpot with 93% compliance over 12 months. Every incident is logged, timestamped, and reported in your monthly SLA report. P1 incidents average <15 minutes MTTR across 60+ managed environments -- that is a measured outcome, not a marketing claim. SLA breaches trigger automatic escalation and service credits. No excuses. No fine print.
View SLA compliance dashboard (live)No context loss. The same team that built your environment transitions to managed services. No handoff to a separate "support team." No knowledge loss. No 90-day ramp-up. During onboarding (weeks 1-4), we audit runbooks, establish SLA baselines, integrate with your Slack/Teams channels, and conduct knowledge transfer sessions with your team. Your 24-hour response SLA begins on Day 1.
Download onboarding checklistManaged services covers Elasticsearch cluster operations: monitoring, optimization, incident response, capacity planning, accelerator integration, and architecture reviews. NOT included: application code debugging, non-Elasticsearch infrastructure management, custom software development, or data pipeline engineering. If you need additional services (migrations, implementations, custom accelerators), we scope and price those separately through our consulting engagement models.
View full engagement modelsYes. After the minimum contract term (12 months for Tier 1/2, 6 months for Tier 3), you can cancel with 60-day notice. During the exit period, we provide complete runbook handoff, knowledge transfer sessions, and full documentation of your environment. No penalties. No retention tactics. If we are not delivering measurable value, you should leave. Our retention rate suggests most do not.
View standard contract exit clauseElastic support is reactive: you file a ticket, they respond within their SLA tier. They are Elasticsearch experts (they built it), but they respond to your problems -- they do not prevent them. We are proactive: monthly architecture reviews, cost optimization, accelerator integration, continuous improvement. Plus, we built your specific environment -- we know your shard strategy, your custom plugins, your edge cases, your business context. Elastic support does not have that implementation context. Their 4-hour SLA requires their premium tier. Our 24-hour SLA is included in every tier.
View comparison tableYour Elasticsearch Operations Team Is Ready
Stop firefighting. Start optimizing. 24/7 coverage. 24-hour response SLA. Team continuity from implementation. Predictable pricing.
Ready to move forward? Custom pricing within 48 hours. | Not sure? 15-minute consultation. No commitment.
OPERATIONAL TRACK RECORD
Proven Operational Excellence Across 60+ Elasticsearch Environments